Our world offers a never-ending stream of visual stimuli,
yet today's vision systems only accurately recognize patterns within a few seconds.
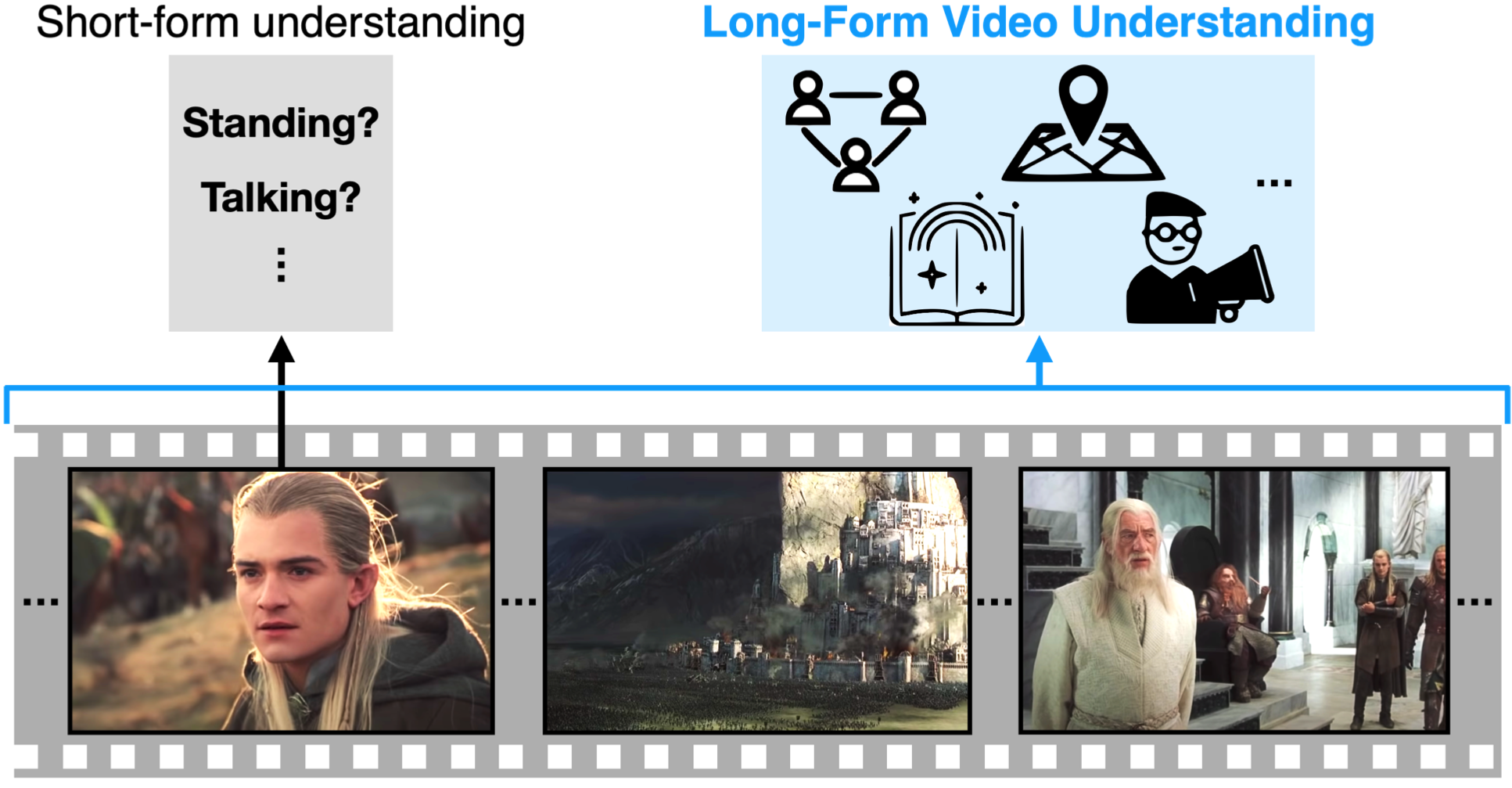
These systems understand the present, but fail to contextualize it in past or future events.
In this paper, we study long-form video understanding.
We introduce a framework for modeling long-form videos and develop evaluation protocols on large-scale datasets.
We show that existing state-of-the-art short-term models are limited for long-form tasks.
A novel object-centric transformer-based video recognition architecture performs significantly better on 7 diverse tasks.
It also outperforms comparable state-of-the-art on the AVA dataset.